

When most people talk about text-to-speech, they’re still thinking in fairly narrow terms: you give the system some text, pick a voice, and it reads the words out loud.
Qwen3-TTS quietly changes that assumption.
With the release of Qwen3-TTS-VD-Flash and Qwen3-TTS-VC-Flash, Alibaba isn’t just improving audio quality or adding more languages. It’s pushing TTS in a different direction altogether—from voice playback toward voice design.
The difference sounds subtle, but once you see how it works, it’s hard to unsee.
From “What to Say” to “How to Say It”
The most important shift in this version of Qwen3-TTS is that voice is no longer treated as a fixed asset.
Traditionally, TTS systems give you two choices:
- clone an existing voice, or
- pick from a small library of preset voices
Qwen3-TTS-VD-Flash breaks out of that box.
Instead of selecting a voice, you describe one.
Through complex natural-language instructions, you can control not just timbre, but also rhythm, emotional tone, speaking style, and even the implied persona behind the voice. The system responds not by approximating an existing speaker, but by synthesizing a new vocal identity that matches your intent.
This is the point where TTS stops being about reading text and starts behaving more like a creative system.
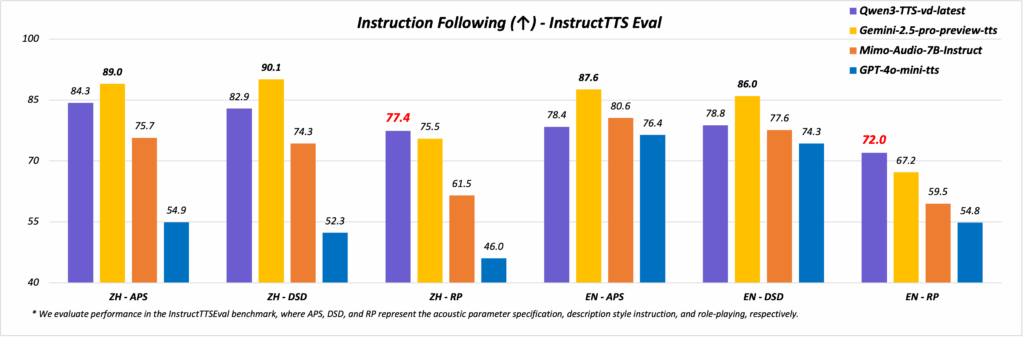
In internal evaluations such as InstructTTS-Eval, this approach has already shown a clear edge over models like GPT-4o-mini-tts and Mimo-audio-7B-instruct. In role-playing scenarios, it even outperforms Gemini-2.5-pro-preview-tts, which is a strong signal that the model understands contextual performance, not just pronunciation.
Voice Cloning That Actually Scales Across Languages
Voice cloning is not new, but reliable multilingual voice cloning still is.
Qwen3-TTS-VC-Flash supports voice cloning with as little as three seconds of reference audio, and—crucially—it can carry that cloned voice across ten major languages, including Chinese, English, German, Japanese, Korean, French, Spanish, and more.
That matters because voice consistency is often where multilingual TTS falls apart. Many systems can clone a voice in one language, but lose its character when switching to another.
On multilingual benchmarks such as the MiniMax TTS Multilingual Test Set, Qwen3-TTS-VC-Flash achieves a lower average word error rate than MiniMax, ElevenLabs, and GPT-4o-Audio-Preview. In practical terms, that translates to speech that not only sounds right, but also stays intelligible and stable across languages.
For global products, this is not a minor improvement—it removes an entire class of compromises.
Text Understanding That Reduces Friction
Another less visible, but equally important improvement lies in text robustness.
Real-world text is messy. It includes lists, mixed languages, inconsistent punctuation, and formatting artifacts that aren’t “clean” by academic standards. Qwen3-TTS-VD-Flash and VC-Flash show strong resilience to this kind of input.
The models can:
- parse complex sentence structures
- identify key semantic units
- handle non-standard or loosely formatted text
without collapsing into awkward pauses or misread emphasis. For anyone building production systems, this reduces the need for heavy preprocessing and manual cleanup.
What This Means in Practice

Taken together, these changes point to a clear direction: Qwen3-TTS is no longer just a speech synthesis model—it’s a voice control system.
It’s particularly well-suited for:
- AI characters and role-based agents
- Products that require branded or persona-driven voices
- Multilingual platforms that need consistency rather than approximation
At the same time, it’s still a model-level solution. Using it effectively requires API integration, infrastructure, and a willingness to work at the system level rather than through a simple interface.
Choosing the Right Level of Abstraction
This is where many users need to pause and be honest with themselves.
If your goal is to experiment with voice design, build AI-driven characters, or deeply integrate speech into a product, Qwen3-TTS offers capabilities that few systems currently match.
If, on the other hand, your primary need is to generate natural-sounding audio quickly—for content, videos, podcasts, or internal use—a higher-level AI voice tool may still be the more practical choice. These tools trade some control for speed and simplicity, which is often the right decision outside of core AI products.
Final Thoughts
Qwen3-TTS doesn’t just improve how speech sounds. It changes how speech is specified.
By allowing users to describe voices rather than select them, and by maintaining expressiveness and consistency across languages, this release moves TTS closer to something creators and developers can truly design with, not just deploy.
Whether that power is worth the added complexity depends on what you’re building—but as a signal of where AI voice is heading, Qwen3-TTS is hard to ignore.